In this article, I’ll show you how can you create a basic chat bot which utilizes the data provided by you. Here we will be using GPT-Index/LlamaIndex, OpenAI and Python.
Let’s get started by installing the required Python module.
Install modules/packages
We need to install, two packages named llama-index and langchain and this can be done using below lines:
pip install llama-index pip install langchain
Importing packages
Next, we need to import those packages so that we can use them:
from llama_index import SimpleDirectoryReader,GPTListIndex,GPTVectorStoreIndex,LLMPredictor,PromptHelper,ServiceContext,StorageContext,load_index_from_storage from langchain import OpenAI import sysPlease note that, here, we don’t need an GPU because we are not doing anything local. All we are doing is using OpenAI server.
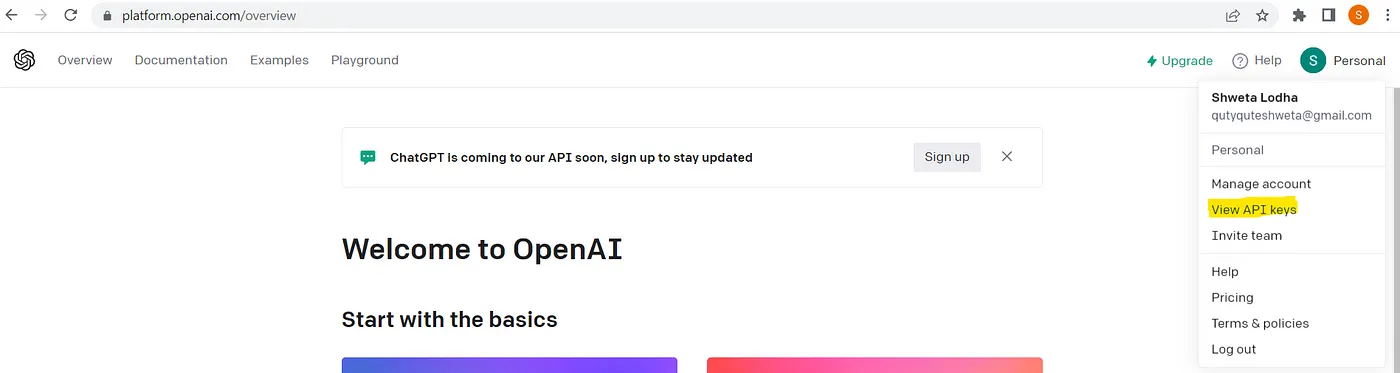
Grab OpenAI Key
To grab the OpenAI key, you need to go to https://openai.com/, login and then grab the keys using highlighted way:
os.environ["OPENAI_API_KEY"] = "YOUR_KEY"
Collect Data
Once our environment is set, next thing we need is data. Here, you can either take an URL having all the data or you can take the data, which is already downloaded and is available in the form of a flat file.
If you are going with URL, then you use wget to download your text file:
!wget <YOUR_URL>/ABC.txt
Once text file is downloaded, make sure to keep it in a directory. If you have multiple text files, you can keep all of them into the same directory.
Now we have the data, we have the knowledge. Next thing is to use this knowledge base.
Create Index
Now, using all the text files, we need to create index. For this, we will create a function, which will take the directory path where our text file is saved.
def create_index(path): max_input = 4096 tokens = 200 chunk_size = 600 #for LLM, we need to define chunk size max_chunk_overlap = 20
promptHelper = PromptHelper(max_input,tokens,max_chunk_overlap,chunk_size_limit=chunk_size) #define prompt
llmPredictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-ada-001",max_tokens=tokens)) #define LLM docs = SimpleDirectoryReader(path).load_data() #load data
#create vector index
service_context = ServiceContext.from_defaults(llm_predictor=llmPredictor,prompt_helper=promptHelper)vectorIndex = GPTVectorStoreIndex.from_documents(documents=docs,service_context=service_context)
vectorIndex.storage_context.persist(persist_dir = 'Store')
Above process is called embedding and you need to do this again, only when new data flows in.
Create Answering System
Next, we need to build a system, which can respond to user. Let’s create a function for that.
def answerMe(question):
storage_context = StorageContext.from_defaults(persist_dir = 'Store')index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
response = query_engine.query(question)
return response
Test The System
Finally, it’s the time to test the system. Run your application, ask some questions and get the response.
I hope you enjoyed creating your basic bot.
If you find any thing which is not clear, feel free to watch my video, demonstrating this entire flow.
Hi Swetha, can you show how to handle a session and users… Trying to build like a chat box where multiple users use it at the same time.
ReplyDeleteHi i am getting error while running the same code can you please help me in solving them
ReplyDeleteThis is the code :-
from gpt_index import SimpleDirectoryReader,GPTListIndex,GPTSimpleVectorIndex,LLMPredictor,PromptHelper
from langchain import OpenAI
import sys
import os
os.environ["OPENAI_API_KEY"] = "**********************************************"
def create_index(path):
max_input = 4096
tokens = 200
chunk_size = 600 #for LLM, we need to define chunk size
max_chunk_overlap = 20
promptHelper = PromptHelper(max_input,tokens,max_chunk_overlap,chunk_size_limit=chunk_size) #define prompt
llmPredictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-ada-001",max_tokens=tokens)) #define LLM
docs = SimpleDirectoryReader(path).load_data() #load data
vectorIndex = GPTSimpleVectorIndex(documents=docs,llm_predictor=llmPredictor,prompt_helper=promptHelper) #create vector index
vectorIndex.save_to_disk('vectorIndex.json')
return vectorIndex
def answerMe(vectorIndex):
vIndex = GPTSimpleVectorIndex.load_from_disk(vectorIndex)
while True:
input = input("Please ask: ")
response = vIndex.query(input,response_mode="compact")
print(f"Response: {response} \n")
aa=create_index("files")
out=answerMe(aa)
and i am getting this error :-
Traceback (most recent call last):
File "c:\Users\dlove\OneDrive\Desktop\work\ChatGpt\demo.py", line 34, in
aa=create_index("files")
File "c:\Users\dlove\OneDrive\Desktop\work\ChatGpt\demo.py", line 19, in create_index
vectorIndex = GPTSimpleVectorIndex(documents=docs,llm_predictor=llmPredictor,prompt_helper=promptHelper) #create vector index
File "C:\Users\dlove\AppData\Local\Programs\Python\Python310\lib\site-packages\gpt_index\indices\vector_store\vector_indices.py", line 94, in __init__
super().__init__(
File "C:\Users\dlove\AppData\Local\Programs\Python\Python310\lib\site-packages\gpt_index\indices\vector_store\base.py", line 57, in __init__
super().__init__(
TypeError: BaseGPTIndex.__init__() got an unexpected keyword argument 'documents'
Lately API has changed. Updated the above code.
DeleteThis comment has been removed by the author.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeletehello, thank you for the sharing !
ReplyDeleteI have built a chat completion system using openAI but the data I am giving to system is more than 6000 tokens. Do you have any suggestions to keep the context and the instructions to bypass the limit?
Hello, thank you so much for sharing this technique, that is very insightful indeed.
ReplyDeleteA first question is about the context limitation of ChatGPT. How does this embeddings/indexing technique via llama_index get around the 4096 token context limit? At the end of the day, I imagine that the query_ending.query(question) process has to provide ChatGPT with some context data. What if the 'Store' represents data that is a magnitude larger that 4096 tokens?
A second question is about GPT models. Looking into the OpenAI usage logs, it looks like embeddings are made using the model "text-embedding-ada-002-v2", which is similar to what is specified when configuring the LLMPredictor above. However, when making the query_engine.query(question) call, it looks like the model used by OpenAI is the "text-davinci" model. Is there a way to control which model is being used at query time? gpt-3.5-turbo for example, which would be a cheaper model.
I would be very grateful if you could point me into the right direction to help with my understanding on those two points.
Many thanks.
I found the answer to the second question by the way, the chat model can be specified at query time by specifying a service_context like this:
DeletemyLLMPredictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo"))
myServiceContext = ServiceContext.from_defaults(llm_predictor=myLLMPredictor)
query_engine = index.as_query_engine(service_context=myServiceContext)
Still unsure about the first question though?
Thank you again.
I think I now understand the first question I asked. The query_engine first assembles the text chunks that are relevant to the question using the embedding vectors and only sends those text chunks to ChatGPT for context, hence hopefully staying within the 4k limit.
DeleteWhat I am most interested in is having chatgpt identify and list the main sections of the whole document so this would be spanning many areas of the document - is there a particular type of index/graph that would be most efficient to that purpose?
Many thanks.
I'm facing this error while execute the python file in which scripts written
ReplyDeleteImportError: DLL load failed while importing interpreter: The specified module could not be found.
Keep a amazing blog i like it
ReplyDelete